![]()
![]()








株式会社IHI様総合重工業メーカー
2017年4月~11月の期間で、航空用ジェットエンジン開発における、三次元圧縮性流体解析プログラムと流体力学シミュレーションプログラムの高速化チューニングを実施しました。
初めに行った性能計測では、16コアを使った自動スレッド並列処理であるにもかかわらず、逐次処理の約4倍もの実行時間がかかってしまっていることを確認しました。また、プロファイルの結果から、整数型load を扱う装置で待ち合わせが発生していることが分かりました。
では、なぜ整数型loadで待ち合わせが発生しているのでしょうか。メトロでは30年間で2700件を超えるチューニングに対応してきたこれまでの知見から、複雑なアセンブラコードの中で目星をつけ、検証と分析を繰り返して原因を絞り込んでいきます。
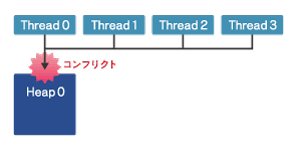
各スレッドからヒープ領域へのallocateでコンフリクトが発生する
real(8), pointer, dimension(:,:):: a
allocate(a(10, 100))
!$omp parallel do shared(ret,a,i) private(j) default(none)
do i=1,1000000
do j=1,10
ret = func_a(a(j,:))
end do
end do
deallocate(a)
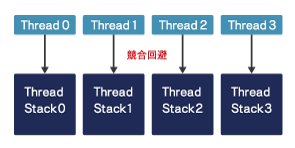
各スレッドごとに確保されているスタック領域を利用することでallocateが不要になりコンフリクトが解消する
real(8), pointer, dimension(:,:):: a
real(8),dimension(100):: q1
allocate(a(10, 100))
!$omp parallel do shared(ret,a,i) private(j,q1) default(none)
do i=1,1000000
do j=1,10
q1(:) = a(j,:) //ローカル配列にコピー
ret = func_a(q1)
end do
end do
deallocate(a)
最もボトルネックになっていたのは、コンパイラが内部で生成するallocate関数が各スレッドから同時期に実行され、大きなコンフリクトが発生していたことでした。
この問題を解決するには複数の手法がありますが、プログラムの特性と環境を考慮した結果、ポインタ配列をローカル配列にコピーして、その配列を引数とすることが最適な手法だと考えられました。これによりローカル配列はスレッドスタック領域に確保されるため、関数を呼び出すたびに発生していたヒープ領域のコンフリクトが解消されます。
今回の事例では改善前と比較して、7.15倍高速化することができました。スレッド並列化はマルチコアを活用する大変有効な手段です。しかし、ハードウェア本来の性能十分に発揮するには、コンパイラとハードウェアを熟知し、並列実行時に発生するボトルネックを正しく分析し適切に対処することが必要となります。
さらに命令レベルの並列性の向上を合わせて行うことで、最終的には9.98 倍の性能向上を実現することが可能になりました。
本事例のPDF資料のダウンロードをご希望される方は、下記フォームにお客様情報をご入力ください。
お客様からいただく個人情報は、情報提供のために使用させていただきます。これにあたり、株式会社メトロからご連絡を取らせていただくことがございます。個人情報の取り扱いについてはプライバシーポリシーをご覧ください。
スーパーコンピュータや組み込み向けアプリケーションの動作が遅くなるボトルネックを解消し、開発・研究にかかる期間の短縮や経費削減に繋げます。
コンパイラの性能改善やアーキテクチャ対応、プログラム言語の新しい規格への対応など、プロセッサの性能を引き出すための独自コンパイラを開発いたします。
まずはお気軽にお電話またはフォームからお問合わせください
営業による訪問、資料請求も承っております。


